안녕하세요
딥러닝이나 머신러닝 프로젝트를 해보신 분들이라면 아마 한 번쯤 이런 생각해보셨을 겁니다
“모델 불러오고, 데이터 전처리하고, 학습시키고, 또 하이퍼파라미터까지 하나하나 조정하려니 너무 귀찮다…”
이런 귀차니즘을 느끼시는 분들 혹은 빠른 프로토타이핑이 필요한 실무자분들에게
유용한 Auto M/L 라이브러리 Pycaret에 대해 소개해보겠습니다
Pycaret?

PyCaret은 Python에서 사용하는 자동화 머신러닝(AutoML) 라이브러리로
Scikit-learn 기반으로 구성되어 있으며, 복잡한 전처리나 모델링 과정을 단 몇 줄의 코드로 처리할 수 있게 도와줍니다.
Scikit-learn, TensorFlow, PyTorch 등 대부분의 머신러닝 프레임워크는 강력하지만, 초기 설정에 시간이 많이 소요되고 반복적인 코드 작성이 불가피하다는 단점이 있습니다. 특히 여러 모델을 테스트해야 할 경우, 코드 복붙만으로 수십 줄이 넘어가고 실수도 생기기 마련이죠. 바로 이런 상황에서 PyCaret은 엄청난 효율을 발휘합니다.
🛠 PyCaret 설치 방법
#pycaret 설치
pip install pycaretPycaret 설치 방법은 pip install pycaret를 통해 간단하게 설치를 할 수 있습니다
단, PyCaret은 내부적으로 scikit-learn, xgboost, lightgbm, catboost, pandas, numpy, matplotlib, seaborn 등의 수십 개의 외부 라이브러리를 사용하고 이러한 라이브러리들은 버전 의존성이 매우 강합니다.
즉, 이미 다른 프로젝트에서 scikit-learn==1.4를 사용 중인데, PyCaret은 1.2.2를 요구하는 식의 충돌이 생길 수 있기 때문에 " PyCaret 설치 시 새로운 가상환경(virtualenv 또는 conda 환경)을 권장드립니다."
PyCaret 사용 순서
pip install을 통해 Pycaret을 설치완료했다면 Pycaret을 import해서 사용하기만 하면 되는데요
Pycaret의 사용법은 다음과 같습니다
1.데이터 준비
2.setup()으로 환경 설정
3.compare_models()로 여러 모델 자동 학습 및 비교
4.create_model()로 특정 모델 학습
5.evaulate_model()로 특정 모델의 성능지표 확인
6.tune_model()로 하이퍼파라미터 튜닝
7.predict_model()로 예측 결과 확인
8.save_model()로 저장
Pycaret 사용 예시(Feat. 분류)
from pycaret.datasets import get_data
from pycaret.classification import *
# 1. 데이터 불러오기
data = get_data('diabetes')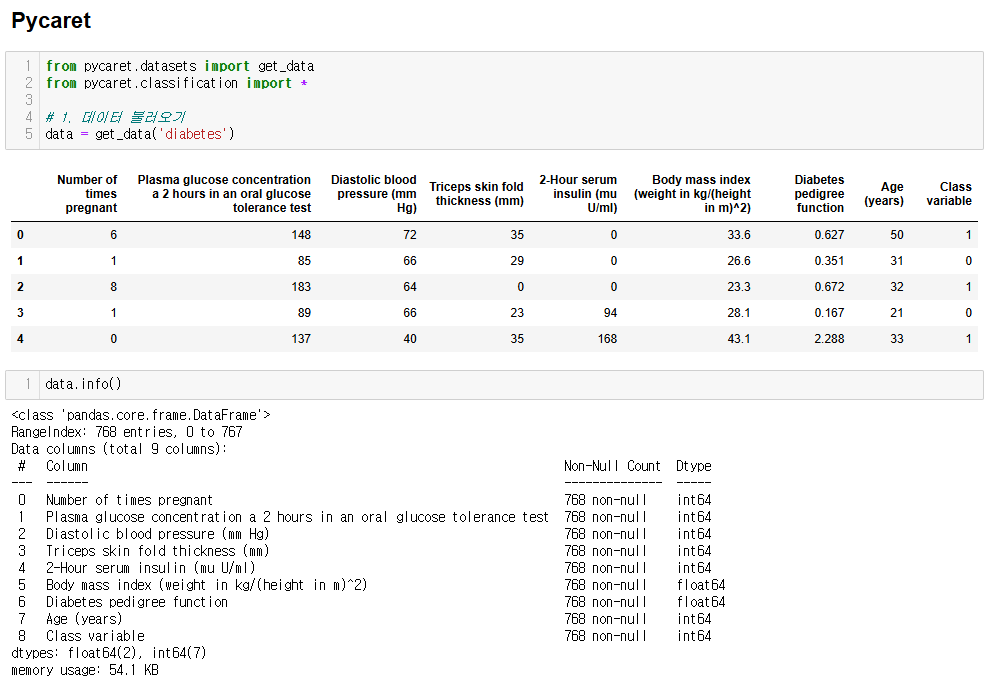
분류모델의 예시로 Pycaret.datasets에 있는 "Diabetes" Data를 활용해 보겠습니다. 먼저 Data를 불러온 뒤 Null값, shape, target value 등 을 확인하기 위해 Data.info() 확인했습니다
# 2. 환경 설정
clf = setup(data, target='Class variable')
환경 설정을 위해 "setup()"을 이용하여 data와 Target Column을 설정해 주면 Auto M/L 사용 준비 끝입니다
# 3. 모델 비교
best_model = compare_models()
compare_models()를 통해 14개의 분류 모델들의 Accuracy, F1_Score, TT(sec) 등 다양한 성능지표로 비교할 수 있습니다 14개의 모델의 성능지표를 비교하고 best model을 선정하는데 제 노트북 기준으로 1분 31초가 걸렸네요
#4.모델 평가
evaluate_model(best_model)compare_models()을 통해 Accuracy값 기준으로 제일 높은 Logistic Regression의 l2 규제를 둔 모델을 선정했고
evaluate_model을 통해 해당 모델의 성능지표를 확인할 수 있습니다
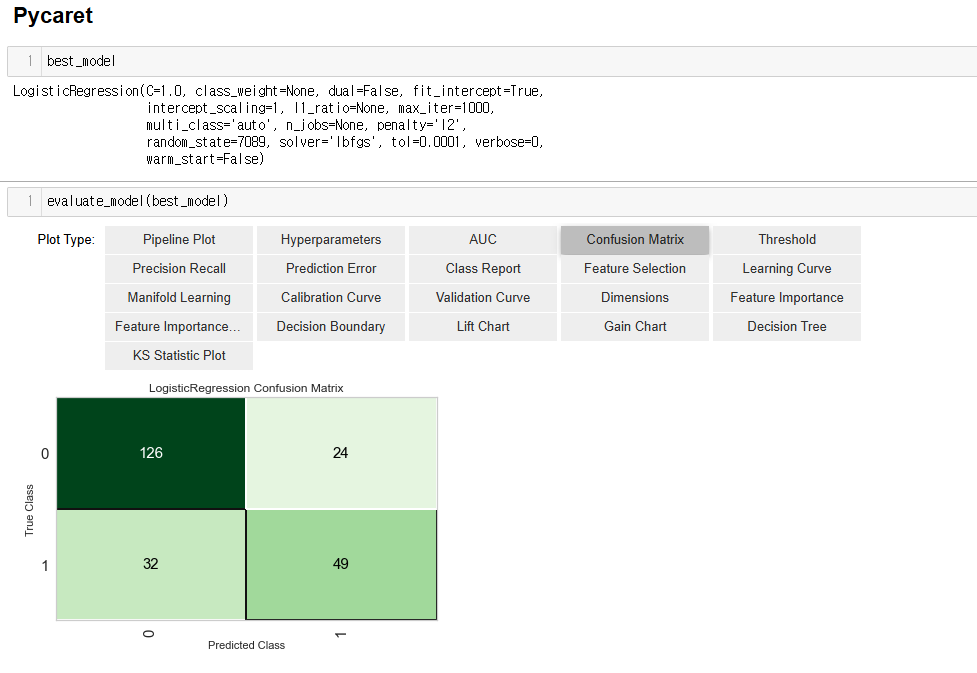
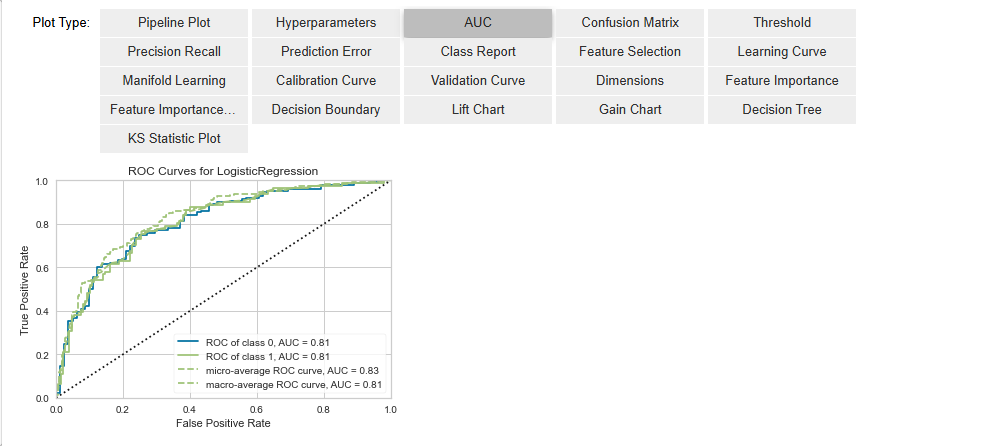


# 5. 예측
df_predict=predict_model(best_model)
본인이 선정한 best model의 성능지표가 기대에 부응했다면 이제 해당 모델로 예측을 할 수 있겠죠?
예측 또한 "predict_model(best_model)" 한 줄의 코드로 labeling과 score값 Column 생성이 가능합니다
#6. 모델 저장
save_model(best_model, 'diabetes_best_clf_model')
학습된 모델을 저장하여 추후에 사용하는 방법 또한 정말 간단합니다
"save_model()" 한 줄의 코드를 통해 모델을 pkl형태로 저장이 가능하며
#7. 모델 불러오기
model_load=load_model("diabetes_best_clf_model")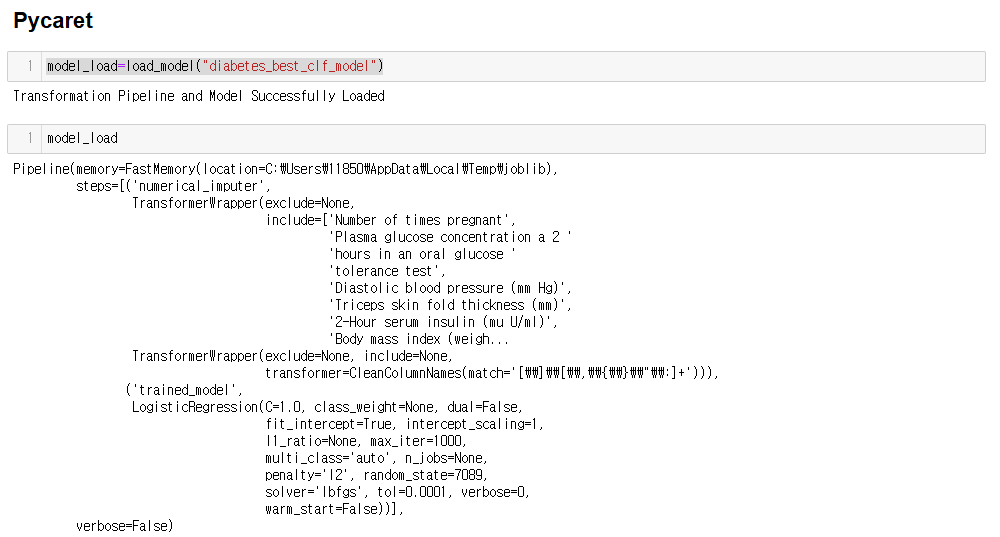
"load_model()" 한 줄의 코드를 통해 저장된 모델을 불러와서 활용할 수 있습니다
PyCaret은 머신러닝 입문자부터 실무 프로토타이핑을 빠르게 해야 하는 실무자까지 폭넓게 활용할 수 있는 훌륭한 도구입니다. 물론 Data가 커질수록 느려지고, 세밀한 커스터마이징에는 한계가 있다는 단점이 존재하지만 데이터 분석/AI 프로젝트를 처음 시작하거나, 복잡한 전처리 및 모델링 과정을 단순화하고 싶다면 한 번 시도해 보시는 걸 추천드립니다
'Python' 카테고리의 다른 글
| Python Dataprep 라이브러리를 이용한 EDA 자동화하기 (0) | 2025.04.14 |
|---|---|
| 파이썬 인코딩 방식 완벽 정리: UTF-8, cp949 오류 해결법까지! (0) | 2025.04.13 |
| Jupyter Notebook에 동영상 삽입하는 방법 (Feat.유튜브) (0) | 2025.04.10 |
| 쥬피터 노트북(Jupyter Notebook) 단축키 모음! 효율적인 코딩을 위한 필수 꿀팁 (0) | 2025.04.06 |